Data Misinterpretation
Jerry Tan
What is Data Profiling?
Profiling is defined by more than just the collection of personal data; it is the use of that data to evaluate certain aspects related to the individual. The intent of this practice is to predict an individual's behaviour and make decisions based on those predictions. In the context of email marketing, a digital profile is used to send a particular targeted email campaign instead of another one.
Based on the definition of data profiling in GDPR, profiling can be defined by three specific elements:
- It implies an automated form of processing;
- It is carried out on personal data
- The purpose of it is to evaluate certain personal aspects of a person to predict their behaviour and make decisions regarding it.
Observation and Questions
Our lives are being quantified by our personal data. The quantified personal data profile is an attempt to tell you who you are and how you behave. Our personal data is scattered on different platforms unevenly. Each part of our data reflects different aspects of ourselves and our lives. Compared with all the data we generate, such incomplete data, can not fully described who we are and how we behave.
People are attached to different users labels because of their sectional datas are collected and analyzed(https://www.comp.nus.edu.sg/~tankl/cs5322/slides/ols.pdf). Based on our own experience we may have found that such labels are not totally accurate . You may have experienced a situation in which a website recommends things you would never be interested in or plays a recommended advertisement which is completely unsuitable for you. Maybe we are attached to wrong labels, and what’s even worse is that the data trades among internet companies often result in the large scale expansion of these wrong digital labels.
Should this be regarded as a form of data prejudice or bias?Would this kind of misinterpretation eventually seriously interfere with the daily life of the data subjects or make them severely misunderstood by others?
Experiment Implementation
I did an experiment that simulates the process of personal data misinterpretation.
First I requested a copy of my data from Apple privacy https://privacy.apple.com .
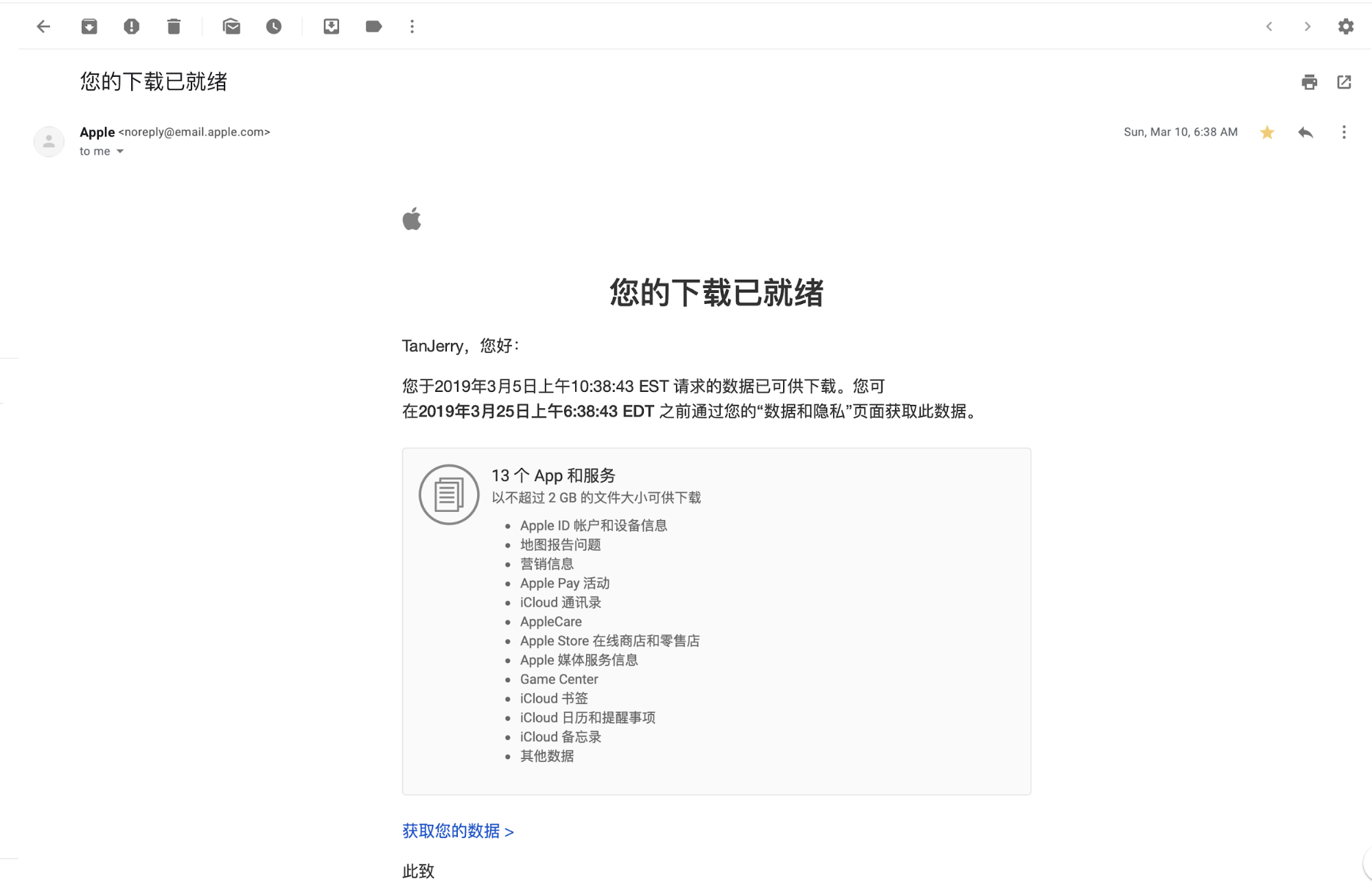
- It took me 7 days to receive a downloadable copy of my personal data. I received an email for Apple privacy, as shown in the picture below, In which I received 13 files with different categories of personal data.
- Apple ID account and device information
- Map report problem
- Marketing information
- Apple Pay activity
- iCloud address book
- AppleCare
- Apple Store online store and retail store
- Apple Media Service Information
- Game Center
- iCloud bookmarks
- iCloud calendar and reminders
- iCloud memo
- Other data



Experiment Findings
In the process of fetching my data from Apple privacy, I found an interesting “bias” of Apple that I can only get a copy of personal data using my Apple ID which was registered in US, but can not get access to requesting a copy of personal data using my Chinese Apple ID.
The reviews / comments/ from experiment participants can be classified into two different kinds of interpretation: direct interpretation and indirect interpretation.
The direct interpretations focus on digging out the facts from the raw data. Experiment participants did credible interpretation of some of my basic personal information. They got to know my school based on the email address I used to register the Apple ID; got to know my nationality based on my Language (system language); got to know my living location based on my Official Location and IP City; got to know I will cook for myself based on my downloading a recipe apps; got to know I will also order food based on my downloading an online food ordering service apps and etc; got to know I like art and design based on my Podcasts subscription list. Most of the direct interpretations are reliably true. However, sometimes errors will occur. For example, some people found an item from my Store Free Transaction History showing that I had an Apps of a high-end hotel and they indicate that that is the place I usually live in during the trip, which is totally not a fact.
The indirect interpretations focus on linking different originally irrelevant data together or connecting raw data with their own living experience, which is more subjective and less credible. For instance, participants drew a conclusion that I am a person who lives a regular life and is good at taking care of myself based on had a recipe Apps and a fitness Apps; some participants gave me a “label” of high quality of life based on the high-end hotel Apps. However, interesting and meaningful speculations can also be found. For instance, a participant found an item of sleep control Apps from the Store Free Transaction History and he also found that I usually use my Apps store in the middle of night based on the time of the Event Data (the data and time of the actions in Apps store) of the Apps and Service Analytics. He drew an interesting conclusion that I often suffer from sleep disorders, which is true.
Conclusion
It is entirely possible for data interpreters to obsess about something that is statistically insignificant, or to omit important variables, simply because they do not understand the entire context of every aspects of my life and merely rely on my mobile personal data, which can only reflect a part of my life. All in all, it is hard to comprehensively understand an individual with the incomplete data. But if all aspects of life can be quantified and become accessible data, maybe it could be a different story.
From my perspective, in the process of the experiment, most of the participants take a top-down approach to data analysis, meaning they focus on explaining the individual items that have been relevant in the past in a same or similar context. They tend to write down their reviews as soon as they found the points. Few of the participants take a bottom-up approach, meaning that they may read as much detailed data as possible so as to generalize an overall character of the subject of the experiment and then try to do judgements on different data. □
Zhizen (Jerry) Tan is a first year MFA candidate at Parsons School of Design studying Design and Technology.
